PlAwAnSaI
Administrator
Google Cloud Architect Accelerated Learning Path for AWS professionals:
.

.
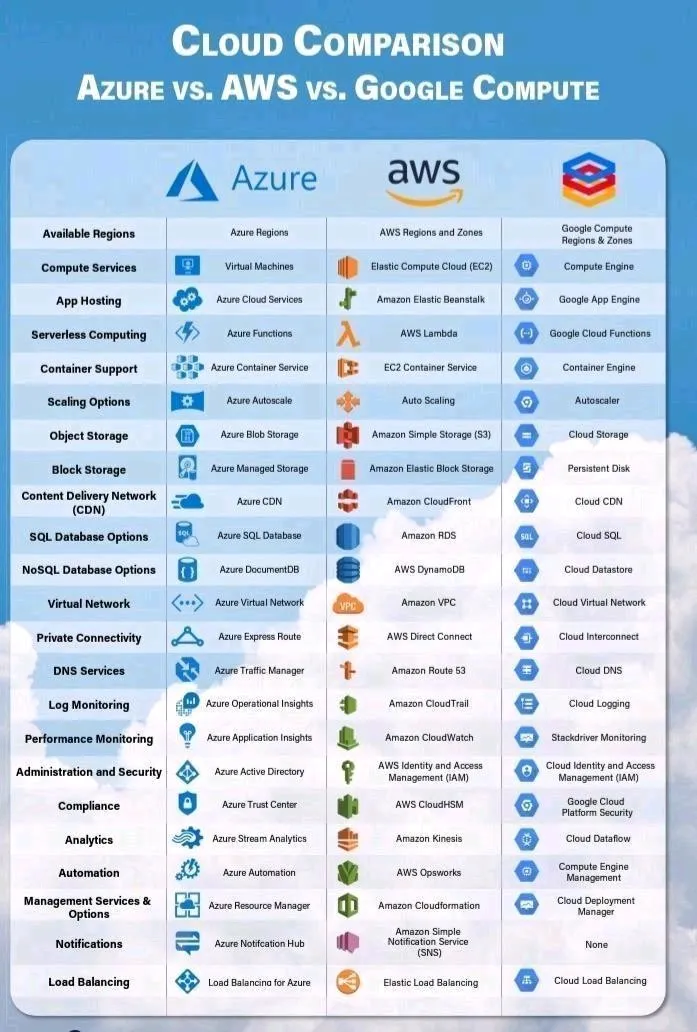
- In AWS, have been using AWS CloudShell for writing and running bash scripts to manage AWS resources without setting up credentials and installing packages on the multiple local machines use. To reimplement scripts in Google Cloud should use Cloud Shell.
- In AWS, there is an admin user, Tamara, who manages the organization with an attached policy that allows all IAM actions on all resources within the organization. Could grant similar permissions in Google Cloud by Add Tamara to an admin group that is assigned the roles/resourcemanager.organizationAdmin on the organization.
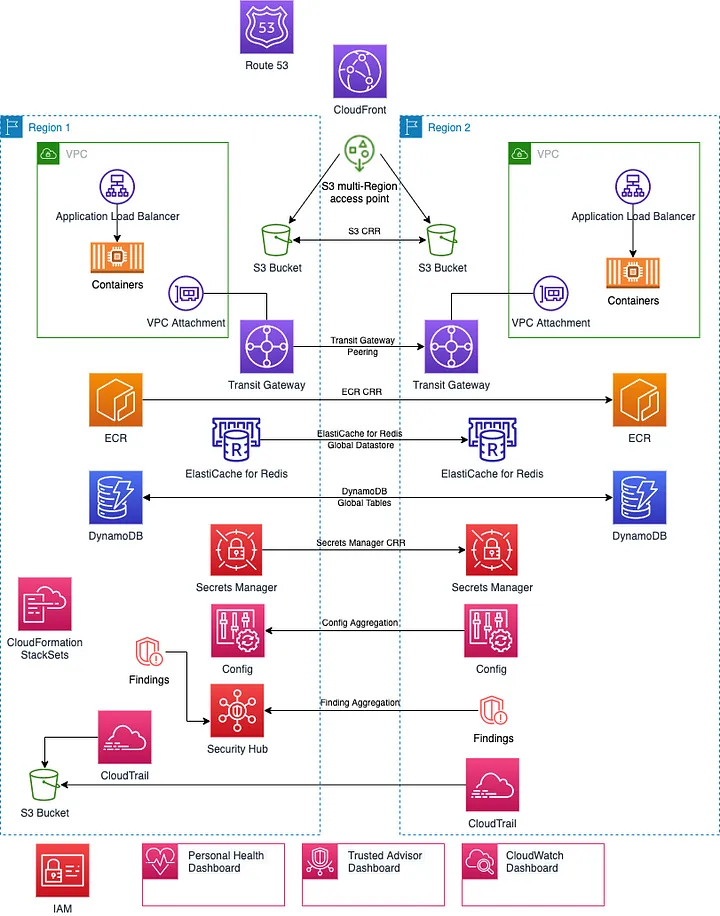
- The AWS resource hierarchy uses organizational units to organize accounts, which then contain resources. Could create a similar hierarchy in Google Cloud with Folders, projects, and resources.
- Alex is a Storage Admin, responsible for managing objects in Cloud Storage. He needs to have the right permissions for every project across the organization. Should Add Alex to a group that has the roles/storage.objectAdmin role assigned at the organizational level.
- In AWS, there is an IAM role and instance profiles set up for use by a web app to access other services and resources. Need to set up the equivalent environment in Google, should use Google Cloud IAM service account.
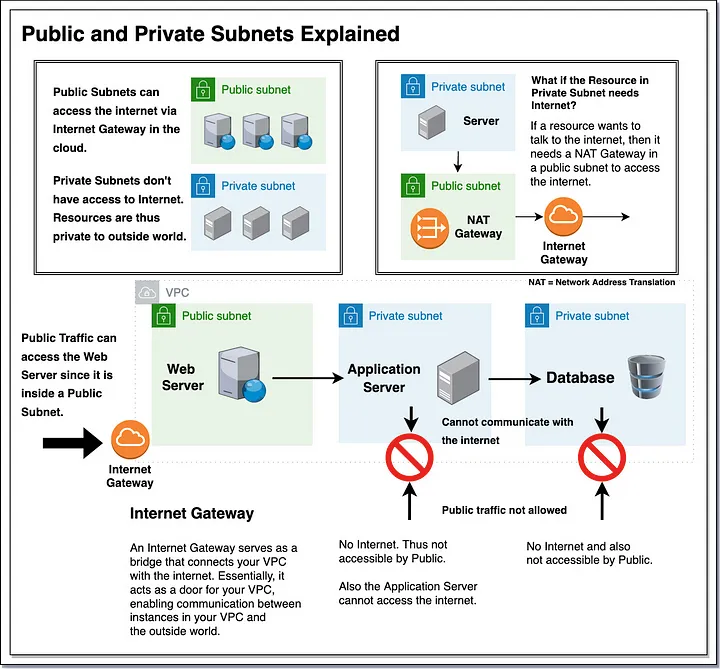
- There is an AWS security group that is set up on a VPC, and then associated with instances. If want to replicate this environment in Google Cloud, should use Google firewall rules defined at the network level.
- If want to connect to Google Workspace and YouTube, but organization cannot meet Google's peering requirements, could use Carrier Peering.
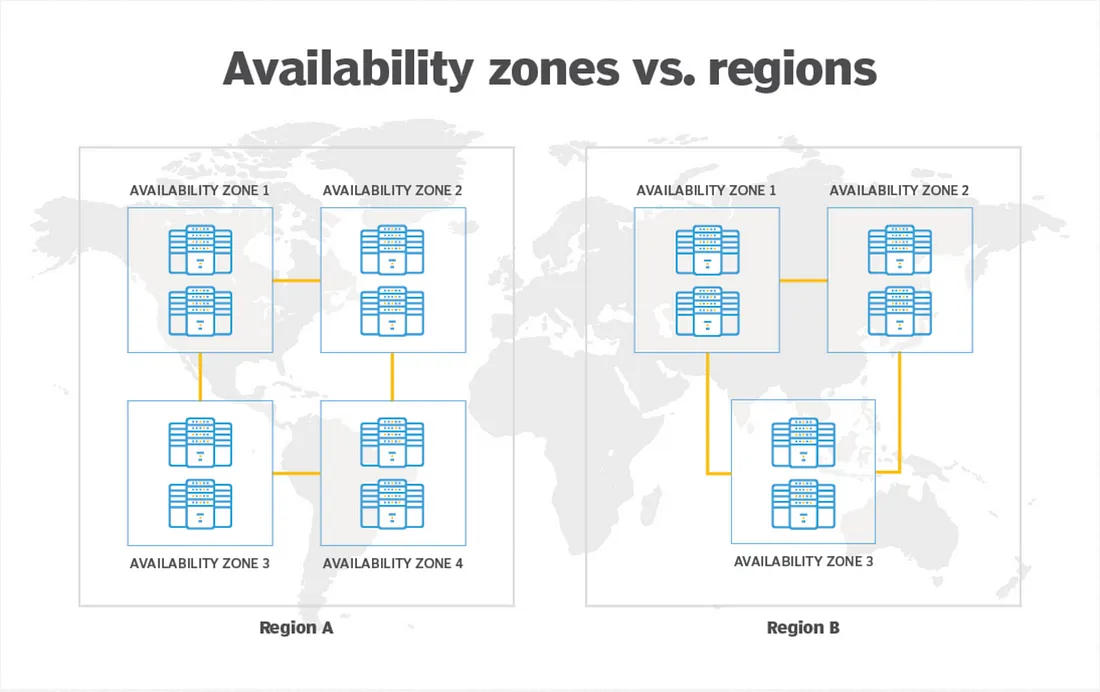
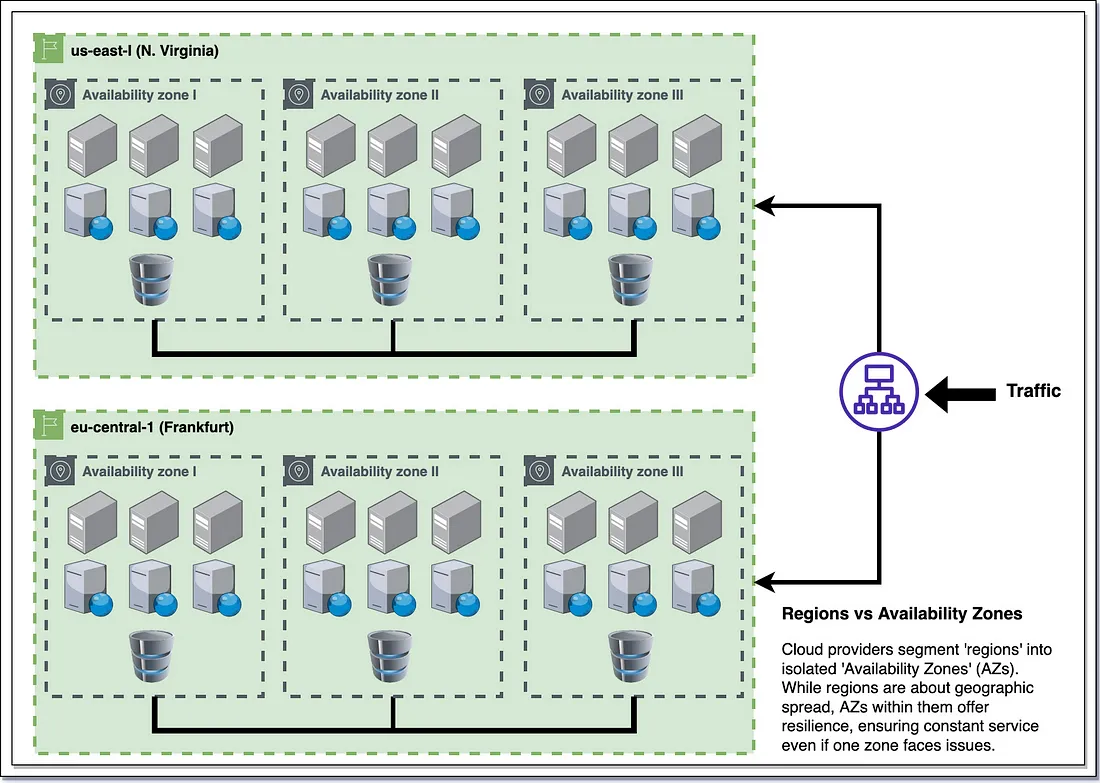
- AWS VPCs are Regional unless they are peered using VPC peering and contain AZ subnets, while Google Cloud VPCs are global, and contain regional subnets/subnets span regions.
- A Cloud Router implements dynamic VPN that allows topology to be discovered and shared automatically, which reduces manual static route maintenance.
- Google Cloud VPC Peering enables to connect two VPC networks from different organizations.
- There is an AWS EC2 instance without an external IP address assigned, but that connects to AWS services and APIs through an AWS NAT Gateway. If want to configure a similar scenario with a Compute Engine VM, should Use Google APIs and services by enabling Private Google Access on the subnet used by the VM's network interface.
Last edited: