PlAwAnSaI
Administrator
- ค่าบริการ EC2:
- Standard Reserved Instance มีส่วนลดให้ เมื่อระบุกลุ่มประเภท Instance และขนาด, สิทธิ์การใช้งานอย่างใดอย่างหนึ่งใน Region 1 แห่ง
โดยจำนวน EC2 Instance ในการเรียกใช้ระบบปฏิบัติการครอบคลุมอยู่ในระยะเวลา 1 ปี หรือ 3 ปี โดย 3 ปีมีส่วนลดให้มากกว่า - EC2 Instance Savings Plans ลดค่าใช้จ่าย EC2 Instance ให้ เมื่อมีข้อผูกมัดในการใช้จ่ายเป็นรายชั่วโมงกับกลุ่มประเภท Instance และ Region เป็นระยะเวลา 1 ปี หรือ 3 ปี
.
- Standard Reserved Instance มีส่วนลดให้ เมื่อระบุกลุ่มประเภท Instance และขนาด, สิทธิ์การใช้งานอย่างใดอย่างหนึ่งใน Region 1 แห่ง
- Elastic Load Balancing: เป็นบริการของ AWS ที่กระจายการรับส่งข้อมูลของ App ขาเข้าโดยอัตโนมัติในทรัพยากรต่างๆ เช่น Amazon EC2 Instance ซึ่งช่วยตรวจสอบให้แน่ใจว่าไม่มีทรัพยากรแม้แต่รายการ/Instance เดียวจะมีการใช้งานมากเกินไป
- Amazon Simple Notification Service (Amazon SNS) เป็นบริการเผยแพร่/สมัครรับข้อมูล ผู้เผยแพร่จะใช้ Amazon SNS Topic เพื่อเผยแพร่ข้อความไปยังผู้สมัครรับข้อมูล ตัวอย่างง่ายๆ > สมมติมี App ขายของ Online
เวลามีคำสั่งซื้อใหม่ → ระบบส่งข้อความไปที่ SNS Topic: "NewOrderTopic"
Subscribers อาจเป็น- Lambda → ไว้ประมวลผลคำสั่งซื้อ
- Email → ส่งแจ้ง Team ขาย
- SMS → แจ้งลูกค้า
สรุปคือ ส่งครั้งเดียว แต่กระจายถึงหลายปลายทางอัตโนมัติ
.
- Amazon SQS เป็นบริการจัด Queue ข้อความ ทำให้นักพัฒนา App สามารถส่ง จัดเก็บ และรับข้อความระหว่างองค์ประกอบ Software ต่างๆ ได้ทุกขนาด Volume โดยไม่มีการสูญเสียข้อความหรือจำเป็นต้องใช้บริการอื่นๆ โดย App จะส่งข้อความเข้าไปใน Queue ผู้ใช้หรือบริการจะเรียกค้นข้อความจาก Queue ประมวลผลข้อความ แล้วลบข้อความออกจาก Queue
- AWS Lambda เป็นบริการที่เรียกใช้ Code ได้โดยไม่จำเป็นต้องจัดสรรหรือจัดการ Server
ในขณะที่ใช้งานธุรกิจจะจ่ายตามเวลาการประมวลผลที่ใช้เท่านั้น โดยจะมีการเก็บค่าบริการเฉพาะเมื่อ Code ของ App ทำงานอยู่เท่านั้น โดยสามารถเรียกใช้ Code สำหรับ App เกือบทุกประเภทหรือบริการ Backend ได้โดยไม่ต้องมีการดูแลจัดการใดๆ
- การติดตั้ง (Deploy), ใช้งาน (Run) และ จัดการ (Manage) App ที่ใช้ Container บน AWS บริการที่เหมาะคือ:
- Amazon Elastic Container Service (ECS) → จัดการคอนเทนเนอร์ง่าย ใช้งานกับ AWS ได้ทันที เหมาะกับคนที่ไม่อยากดูแล Kubernetes เอง หรือ
- Amazon Elastic Kubernetes Service (EKS) → ใช้ Kubernetes แบบ Managed Service เหมาะถ้าต้องการมาตรฐาน Kubernetes และความยืดหยุ่นสูง

Thai ComPuter Engineer - ThaiCPE
หลายคนยังตัดสินใจไม่ถูกระหว่างใช้ CI/CD กับ ECS vs EKS (Auto Mode) https://www.facebook.com/share/p/19j14LK9r6 โดยเฉพาะในงานที่ต้องการความง่ายและยืดหยุ่นแบบ DevOps-friendly เรามาเทียบให้ชัดๆ...www.facebook.com
- Region ประกอบด้วย Availability Zone (AZ) อย่างน้อย 3 แห่ง
ตัวอย่างเช่น Region ของไทย คือ ap-southeast-7 ซึ่งจะประกอบด้วย AZ 3 แห่ง ได้แก่ ap-southeast-7a, ap-southeast-7b และ ap-southeast-7c
- เมื่อเลือก Region ควรพิจารณา:
- การปฏิบัติตามข้อกำหนดด้านการกำกับดูแลข้อมูลและข้อกำหนดทางกฎหมาย
- ระยะใกล้เคียงกับลูกค้า
- ค่าบริการ และ
- บริการที่มีอยู่ใน Region
.
- AZ คือ ศูนย์ข้อมูลแห่งเดียวหรือกลุ่มศูนย์ข้อมูลภายใน Region ที่แยกกันโดยสมบูรณ์ของโครงสร้างพื้นฐานทั่วโลกของ AWS โดยแต่ละแห่งจะตั้งอยู่ห่างจากกันหลายสิบ Kilometer

Cloud Space TH
หลายคนอาจสงสัยว่า AWS Region คืออะไร❓ 1 ประเทศจะมี 1 Region หรือเปล่า ❓ คำตอบคือไม่ใช่เสมอไปครับ เพราะว่าในบางประเทศ เช่น อเมริกา 🇺🇸 ก็มีหลาย Region เช่น N. Virginia, Oregon และ Region อื่น ๆ...
- Amazon CloudFront เป็นบริการส่งมอบเนื้อหา โดยบริการนี้ใช้เครือข่าย Edge Location ในการ Cache เนื้อหาและส่งมอบเนื้อหาให้กับลูกค้าทั่วทุกมุมโลก เมื่อเนื้อหาได้รับการ Cache ก็จะถูกจัดเก็บไว้เป็นสำเนาในเครื่อง เนื้อหานี้อาจเป็น File Video, รูปภาพ, หน้า Web, และอื่นๆ

Thai ComPuter Engineer - ThaiCPE
CDN คืออิหยัง? เข้าใจง่ายๆ ใน 5 นาที: https://www.facebook.com/share/p/1DjdxxuerG . https://www.maimem.com/cdn-options-beyond-cloudflare
- ด้วย AWS Outposts สามารถขยายโครงสร้างพื้นฐานและบริการของ AWS ไปยังตำแหน่งที่ตั้งต่างๆ ซึ่งรวมถึงศูนย์ข้อมูลในองค์กร
- Subnet คือส่วนของ VPC ที่สามารถจัดกลุ่มทรัพยากรตามความต้องการด้านความปลอดภัยหรือการดำเนินการได้ อาจเป็นแบบสาธารณะหรือแบบส่วนตัวก็ได้
- Subnet สาธารณะมีทรัพยากรที่ต้องสามารถเข้าถึงได้จากสาธารณะ/Internet เช่น Website ของร้านค้า Online
- Subnet ส่วนตัวมีทรัพยากรที่ควรสามารถเข้าถึงได้ผ่านทางเครือข่ายส่วนตัวเท่านั้น เช่น ฐานข้อมูลที่มีข้อมูลส่วนบุคคลและประวัติการสั่งซื้อของลูกค้า
- AWS Direct Connect สามารถนำไปใช้เพื่อสร้างการเชื่อมต่อแบบ Dedicated ส่วนตัวระหว่างศูนย์ข้อมูลของบริษัทกับ AWS ได้
- รายการควบคุมสิทธิ์เข้าถึง (ACL) สำหรับเครือข่ายดำเนินการกรอง Packet แบบ Stateless โดยจะไม่จดจำข้อมูลใดๆ และจะตรวจสอบ Packet ที่ข้ามขอบเขตของ Subnet ทุกครั้งทั้งขาเข้าและขาออก
บัญชี AWS แต่ละบัญชีจะมี ACL สำหรับเครือข่ายที่เป็นค่าเริ่มต้น เมื่อกำหนดค่า VPC สามารถใช้ ACL สำหรับเครือข่ายที่เป็นค่าเริ่มต้นของบัญชี หรือสร้าง ACL สำหรับเครือข่ายแบบกำหนดเองก็ได้
ตามค่าเริ่มต้นแล้ว ACL สำหรับเครือข่ายที่เป็นค่าเริ่มต้นของบัญชีจะอนุญาตให้มีการรับส่งข้อมูลขาเข้าและขาออกทั้งหมด แต่สามารถปรับเปลี่ยนการตั้งค่านี้ได้โดยเพิ่มกฎของตนเอง
ส่วน ACL สำหรับเครือข่ายแบบกำหนดเองนั้น การรับส่งข้อมูลขาเข้าและขาออกทั้งหมดจะถูกปฏิเสธจนกว่าจะเพิ่มกฎเพื่อระบุว่าการรับส่งข้อมูลใดที่ควรได้รับอนุญาต นอกจากนี้ ACL สำหรับเครือข่ายทั้งหมดยังมีกฎการปฏิเสธโดย Default อีกด้วย กฎนี้มีไว้เพื่อให้แน่ใจว่าหาก Packet ไม่ตรงกับกฎใดในรายการ Packet ดังกล่าวก็จะถูกปฏิเสธ
เหมือน รายชื่อแขกในงานสัมนา → ACL ที่อนุญาตให้เฉพาะชื่อใน List เข้าไปในงานได้
รายชื่อแขกในงานสัมนา → ACL ที่อนุญาตให้เฉพาะชื่อใน List เข้าไปในงานได้
- Security Group (SG) คือ Firewall เสมือนที่ควบคุมการรับส่งข้อมูลขาเข้าและขาออกสำหรับ Amazon EC2 Instance
ตามค่าเริ่มต้นแล้ว SG จะปฏิเสธการรับส่งข้อมูลขาเข้าทั้งหมด และจะอนุญาตการรับส่งข้อมูลขาออกทั้งหมด แต่สามารถเพิ่มกฎแบบกำหนดเองเพื่อให้เหมาะกับความต้องการด้านการดำเนินการและความปลอดภัย เป็นแบบ Stateful ซึ่งหมายความว่าถ้ามี Request ขาออก (เช่น EC2 → Internet) ผ่าน SG ได้ → Response ขากลับเข้ามา จะถูกอนุญาต อัตโนมัติ โดยไม่ต้องใส่ Inbound Rule เพิ่มเติม
- Internet gateway ใช้ในการเชื่อมต่อ VPC กับ Internet

- AWS Direct Connect เป็นบริการที่สร้างการเชื่อมต่อส่วนตัวแบบ Dedicated ระหว่างศูนย์ข้อมูลในองค์กรกับ VPC ช่วยให้สามารถลดค่าใช้จ่ายในส่วนของเครือข่าย และเพิ่มปริมาณ Bandwidth ที่สามารถส่งผ่านเครือข่ายได้
- การสืบค้น DNS คือ การแปลงชื่อ Domain เป็นที่อยู่ IP
ตัวอย่างเช่น หากต้องการเข้าชม Website ของ AnyCompany.cz ต้องป้อนชื่อ Domain ลงใน PC และคำขอนี้จะถูกส่งไปยัง Server DNS มันจะขอที่อยู่ IP กับ Website ของ AnyCompany จาก Web Server โดย Web Server จะตอบกลับโดยให้ที่อยู่ IP หมายเลข 193.84.128.201 สำหรับ Website ของ AnyCompany
- Instance Storage เหมาะสำหรับข้อมูลชั่วคราวที่ไม่จำเป็นต้องเก็บไว้ในระยะยาว เมื่อหยุดหรือ Terminate Amazon EC2 Instance ระบบจะลบข้อมูลทั้งหมดที่เขียนที่ Attach ไว้
- Amazon EBS เหมาะสำหรับข้อมูลที่ต้องเก็บรักษา เหมือนแยก Drive ออกจาก Computer Host ของ EC2 Instance
- EBS Volume ต้องอยู่ใน AZ เดียวกันกับ Amazon EC2 Instance ที่ Attach ไว้
ข้อมูลในระบบ File Amazon EFS สามารถเข้าถึงได้พร้อมกันจากทุก AZ ใน Region ที่ระบบ File ตั้งอยู่
- Class ของพื้นที่เก็บข้อมูล S3 Standard-Infrequent Access (IA) เหมาะอย่างยิ่งสำหรับข้อมูลที่ไม่ได้มีการเข้าถึงบ่อยครั้ง แต่ต้องมีความพร้อมใช้งานสูงเมื่อจำเป็น ทั้ง S3 Standard และ S3 Standard-IA จัดเก็บข้อมูลไว้ใน AZ อย่างน้อย 3 แห่ง S3 Standard-IA มีความพร้อมใช้งานในระดับเดียวกับ S3 Standard แต่มีค่าบริการพื้นที่เก็บข้อมูลต่ำกว่า

Thai ComPuter Engineer - ThaiCPE
วันก่อนรู้จัก Compute กันไปแล้ว วันนี้มารู้จัก AWS Storage กันคับ คุณ Sumbul อธิบายไว้ดีมาก: https://medium.com/@sumbul.first/story-of-aws-storage-3d1934c1a336 ....
-
Code:
https://www.linkedin.com/pulse/understanding-amazon-s3-storage-classes-making-most-cloud-ajit-pisal

 คนที่เลือก Storage Class ไม่ถูก หรือไม่อยากมานั่งคอยเปลี่ยนเอง AWS ก็ทำ S3 Intelligent-Tiering มาเผื่อ
คนที่เลือก Storage Class ไม่ถูก หรือไม่อยากมานั่งคอยเปลี่ยนเอง AWS ก็ทำ S3 Intelligent-Tiering มาเผื่อ
หลักการคือ มันจะ “ย้าย File อัตโนมัติ” ระหว่าง Tier (เช่น Frequent, Infrequent, Archive) ตามพฤติกรรมการเข้าถึง File โดยไม่ต้องคิดเองว่าจะเก็บไว้ Class ไหน
มันจะ “ย้าย File อัตโนมัติ” ระหว่าง Tier (เช่น Frequent, Infrequent, Archive) ตามพฤติกรรมการเข้าถึง File โดยไม่ต้องคิดเองว่าจะเก็บไว้ Class ไหน
ทำงานยังไง:- เมื่อ Upload File เข้า Intelligent-Tiering → มันจะเริ่มเก็บไว้ใน Frequent Access Tier
- ถ้า 30 วันไม่ได้ถูกอ่านเลย → มันจะย้ายไป Infrequent Access Tier (ถูกกว่า)
- ถ้า 90 วันไม่ถูกอ่าน → ย้ายไป Archive Instant Access Tier
- ถ้า 180 วันไม่ถูกอ่าน → ย้ายไป Archive Access หรือ Deep Archive Access ตามที่ตั้งค่าไว้


Last edited:

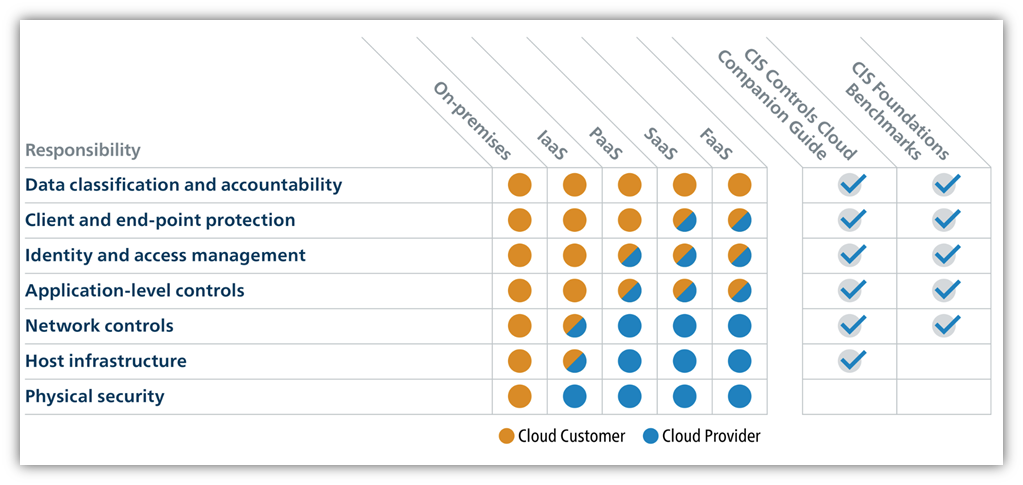
 IAM Policy เอกสารที่ให้หรือปฏิเสธสิทธิ์ในบริการและทรัพยากรของ AWS ในระดับบัญชี Account
IAM Policy เอกสารที่ให้หรือปฏิเสธสิทธิ์ในบริการและทรัพยากรของ AWS ในระดับบัญชี Account Service Control Policy (SCP) (ในระดับองค์กร Organization)
Service Control Policy (SCP) (ในระดับองค์กร Organization)

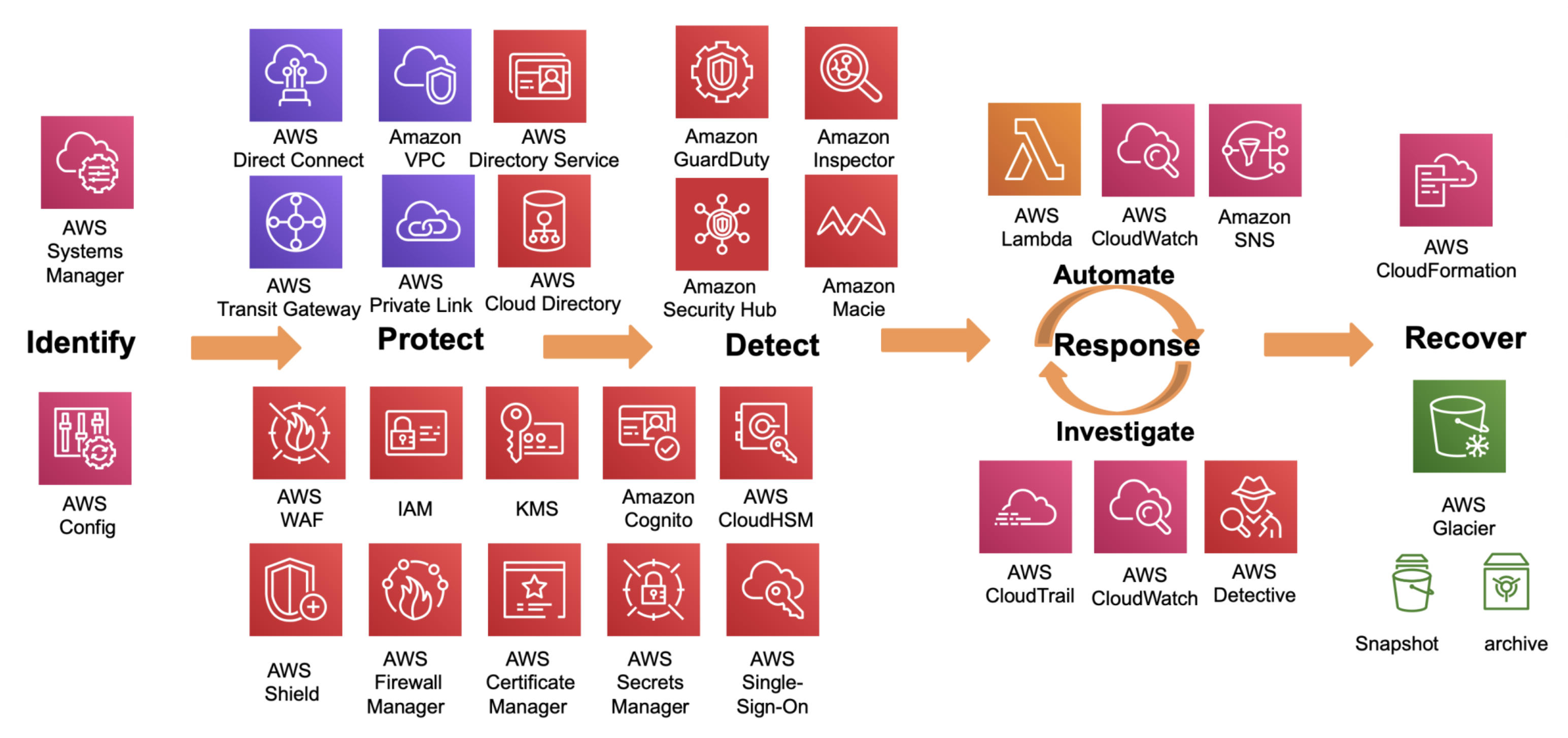
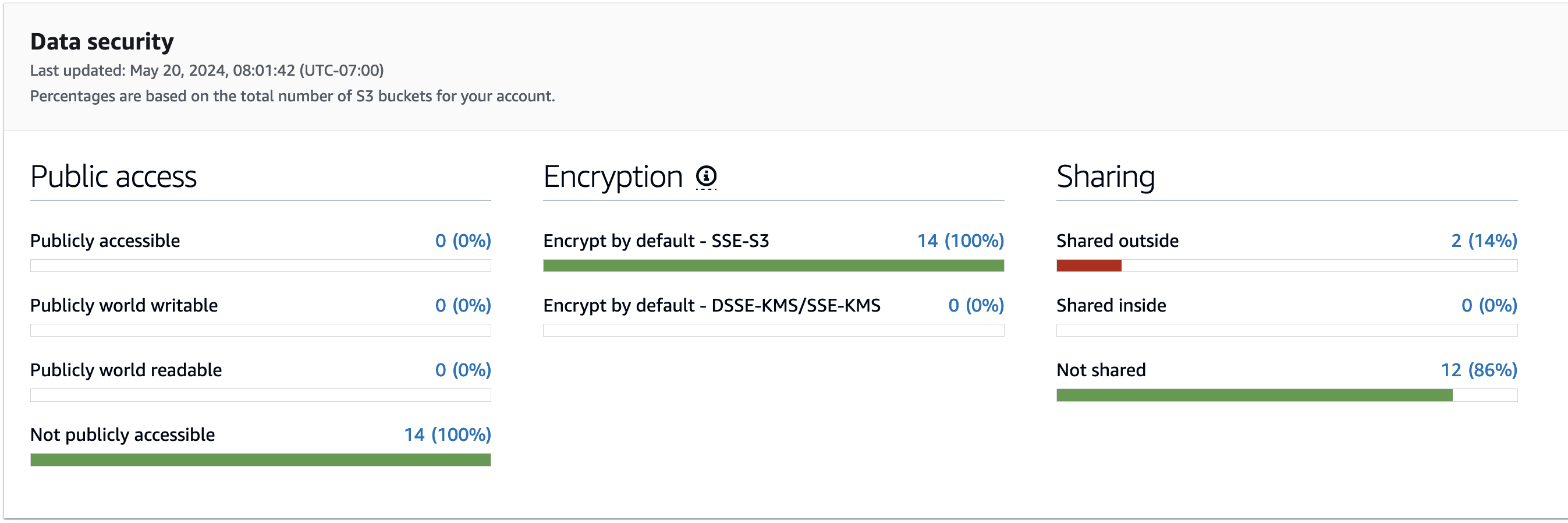




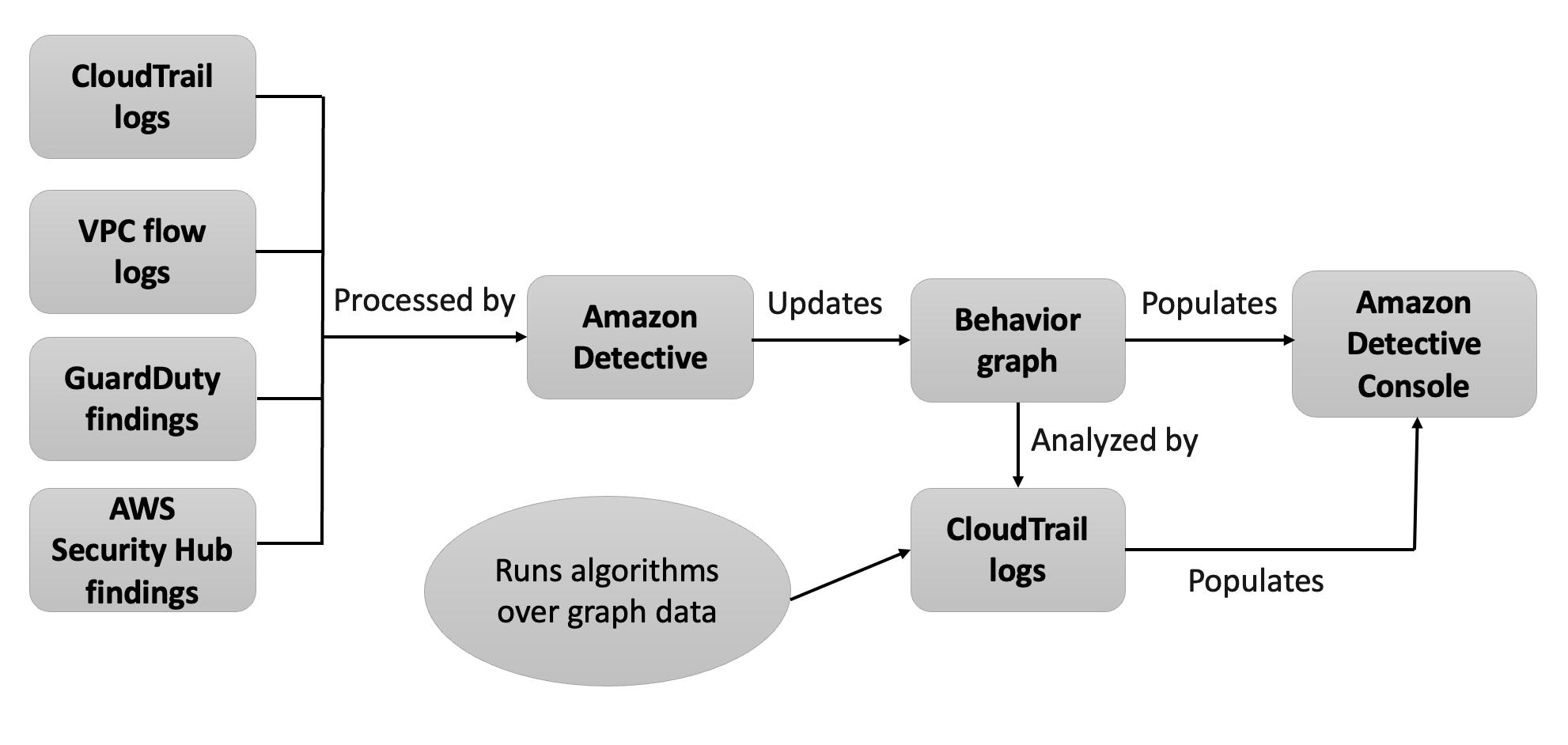

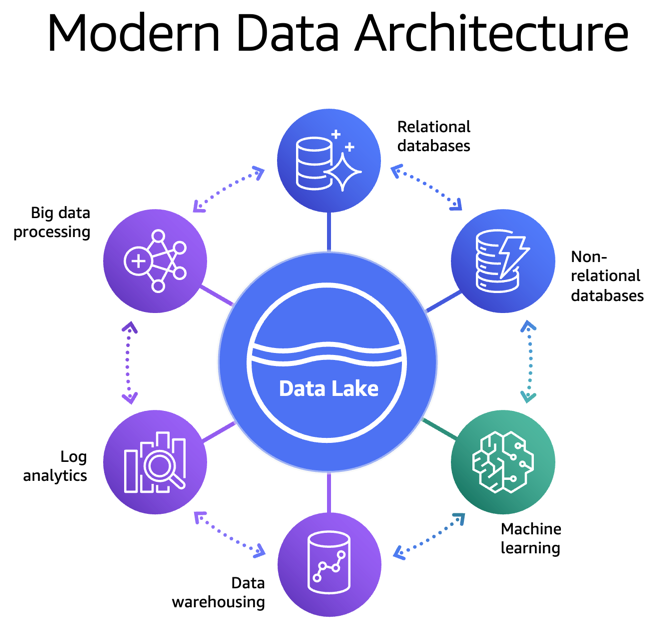
 VPC Flow Logs จะบันทึกข้อมูล Network Traffic ที่เข้าออก ENI (Elastic Network Interface) ของ EC2
VPC Flow Logs จะบันทึกข้อมูล Network Traffic ที่เข้าออก ENI (Elastic Network Interface) ของ EC2 หาแหล่งข้อมูล (Identify Data Source) เช่น ข้อมูลจาก Database, API, Log, Excel หรือระบบต่าง ๆ
หาแหล่งข้อมูล (Identify Data Source) เช่น ข้อมูลจาก Database, API, Log, Excel หรือระบบต่าง ๆ ระบุผู้เกี่ยวข้อง (Stakeholder) เช่น Business User, Data Analyst, Data Engineer หรือ Team อื่นที่ใช้ข้อมูล
ระบุผู้เกี่ยวข้อง (Stakeholder) เช่น Business User, Data Analyst, Data Engineer หรือ Team อื่นที่ใช้ข้อมูล ทำความเข้าใจข้อมูล (Understand Data) ข้อมูลมีความหมายอะไร คุณภาพเป็นอย่างไร มีข้อจำกัดหรือไม่
ทำความเข้าใจข้อมูล (Understand Data) ข้อมูลมีความหมายอะไร คุณภาพเป็นอย่างไร มีข้อจำกัดหรือไม่ หาวิธีสร้างคุณค่าจากข้อมูล (Define Use Case) เช่น ทำ Dashboard, วิเคราะห์พฤติกรรมลูกค้า หรือสร้าง Model ML
หาวิธีสร้างคุณค่าจากข้อมูล (Define Use Case) เช่น ทำ Dashboard, วิเคราะห์พฤติกรรมลูกค้า หรือสร้าง Model ML ฝ่ายขาย (Sales) มีฐานข้อมูลลูกค้าของตัวเอง
ฝ่ายขาย (Sales) มีฐานข้อมูลลูกค้าของตัวเอง การตลาด (Marketing) มีข้อมูล Campaign ของตัวเอง
การตลาด (Marketing) มีข้อมูล Campaign ของตัวเอง ฝ่ายบริการลูกค้า (Support) มีข้อมูลการร้องเรียนของตัวเอง
ฝ่ายบริการลูกค้า (Support) มีข้อมูลการร้องเรียนของตัวเอง "เอาเข้า → เก็บ → จัดหมวด → ประมวลผล → ส่งมอบ"
"เอาเข้า → เก็บ → จัดหมวด → ประมวลผล → ส่งมอบ"