PlAwAnSaI
Administrator
Code:
https://crishantha.medium.com/608d01231ce1มีกลไกการเข้ารหัสสองประเภทที่พบภายใน AWS S3
- การเข้ารหัสฝั่ง Client — ข้อมูลถูกเข้ารหัสในฝั่ง Client ก่อนที่ข้อมูลที่เข้ารหัสจะถูกโยนไปยังฝั่ง Server (S3) การจัดการ Key ทั้งหมดและกระบวนการเข้ารหัสเกิดขึ้นในฝั่ง Client ดังนั้นจึงมีความรับผิดชอบที่จำกัดมากต่อฝั่ง Server S3
- การเข้ารหัสฝั่ง Server — ข้อมูลถูกเข้ารหัสในฝั่ง Server
Post นี้จะกล่าวถึงแง่มุมต่างๆ ของการเข้ารหัสฝั่ง Server S3 เป็นหลัก
วิธีการเข้ารหัสฝั่ง Server S3 มีอยู่สามประเภท
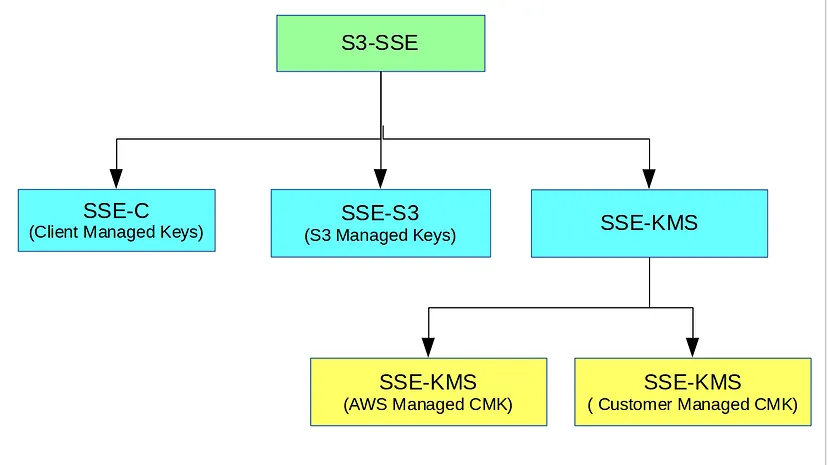
- การเข้ารหัสฝั่ง Server ด้วย Key ที่ลูกค้าจัดเตรียมไว้ (SSE-C)
- การเข้ารหัสฝั่ง Server ด้วย AWS S3 Managed Keys (SSE-S3)
- การเข้ารหัสฝั่ง Server ด้วย AWS KMS (SSE-KMS) — สามารถแบ่งเพิ่มเติมได้อีกสองวิธี (AWS Managed CMK และ CMK ที่จัดการโดยลูกค้า)
SSE-C:
ในวิธีนี้ Client จะเก็บ Overhead ของการจัดการ Key ไว้ และ S3 จะเก็บ Overhead ของกระบวนการเข้ารหัสไว้
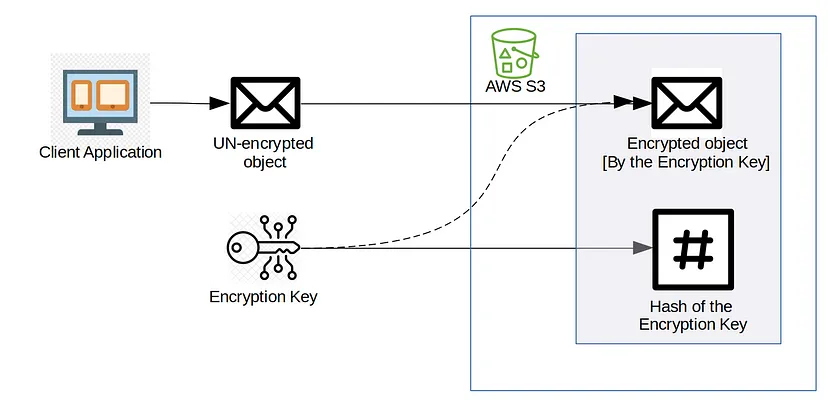
- App Client ต้องจัดเตรียม Object ที่ไม่ได้เข้ารหัสและ “Key การเข้ารหัส” ให้กับ S3
- “Key การเข้ารหัส” จะถูก Hash และจัดเก็บพร้อมกับ Object ที่เข้ารหัส
- จากนั้น S3 จะใช้ “Key การเข้ารหัส” เพื่อเข้ารหัส Object และทิ้ง “Key การเข้ารหัส”
SSE-S3:

ในวิธีนี้ S3 จะจัดการทั้ง Key และกระบวนการเข้ารหัส
การเข้ารหัสเกิดขึ้นด้วยความช่วยเหลือของ AWS S3 ที่สร้าง “Key Root/Master” ซึ่งอยู่ภายใต้การควบคุมโดย AWS S3 ทั้งหมด
- “Key Root/Master” ของ AWS S3 นี้สร้าง “Key ข้อมูล” แยกต่างหากสำหรับแต่ละ Object ที่ Upload ไปยัง S3
- “Key ข้อมูล” ใช้เพื่อเข้ารหัส Object
- AWS S3 “Root/Master Key ถูกใช้เพื่อเข้ารหัส “Key ข้อมูล”
- จากนั้นทั้ง “Object ที่เข้ารหัส” และ “Key ข้อมูลที่เข้ารหัส” จะถูกจัดเก็บไว้ใน S3
- จากนั้น “Key ข้อมูล” ที่สร้างขึ้นจะถูกลบหลังจากกระบวนการเข้ารหัส
- เนื่องจากนี่คือการเข้ารหัสแบบ Symmetric การถอดรหัสของ Object จึงทำได้โดยใช้ "Key Root/Master" ของ AWS S3 เพื่อถอดรหัส “Key ข้อมูล” ที่เข้ารหัส ซึ่งจากนั้นสามารถใช้เพื่อถอดรหัส Object ได้
แม้ว่านี่จะเป็นวิธีการเข้ารหัสโดย Default แต่ก็มีข้อจำกัดบางประการ โดยเฉพาะอย่างยิ่งหากคุณทำไปใช้ใน Environment ที่เข้มงวด เช่น รัฐบาล ที่การปกป้องข้อมูลเป็นสิ่งสำคัญ
ข้อจำกัดที่ว่า:
- ทั้ง “Key Master/Root” และ Key ข้อมูลที่เกี่ยวข้องได้รับการจัดการโดย AWS ทั้งหมด ผู้ใช้ไม่สามารถควบคุม Key เหล่านี้ได้ ใน Environment กฎระเบียบทั่วไป นี่เป็นปัญหาที่ชัดเจน
- ไม่สามารถเปลี่ยน Key ได้ — นี่เป็นความเสี่ยงด้านความปลอดภัยที่อาจเกิดขึ้นได้ในระยะยาว
- ไม่สามารถแยกบทบาทได้ — ใน SSE-S3 ผู้ดูแลระบบที่มีสิทธิ์เข้าถึง S3 สามารถถอดรหัสข้อมูลได้อย่างง่ายดาย นั่นหมายความว่า คุณไม่สามารถจำกัดผู้ดูแลระบบไม่ให้มีความสามารถในการถอดรหัสได้ นี่เป็นข้อกังวลอย่างยิ่งโดยเฉพาะใน Environment ที่เข้มงวด
SSE-KMS:
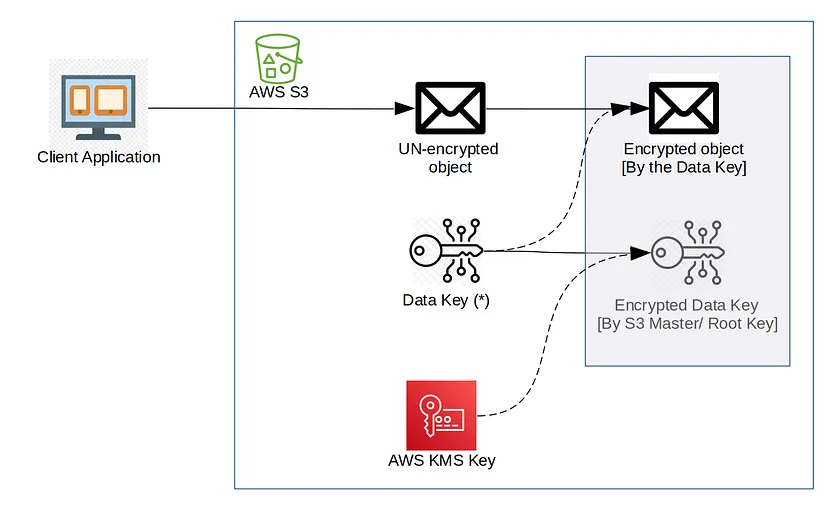
ในวิธีการนี้ AWS มอบหมาย “Key Root/Master” ให้กับ “Key KMS” ของ AWS ซึ่งช่วยให้มี Solution ที่ยืดหยุ่นมากขึ้นในแง่ของการแก้ไขข้อบกพร่องบางประการที่ได้กล่าวไว้ก่อนหน้านี้
- “Key KMS” ของ AWS สามารถสร้าง “Key ข้อมูล” ที่ไม่ซ้ำกันเพื่อเข้ารหัสแต่ละ Object ที่ Upload ไปยัง S3 ค่อนข้างคล้ายกับวิธี SSE-S3 แต่จะแทนที่ "Key Root/Master" ของ SSE-S3 ด้วย "Key KMS" ของ AWS
- ด้วยแนวทาง AWS “KMS Key” คุณจะสามารถสร้าง “KMS Key” ของคุณเองได้ ซึ่งเรียกว่า “CMK ที่จัดการโดยลูกค้า” โดยพื้นฐานแล้วจะช่วยให้คุณสามารถ Apply Permission, เปลี่ยน Key และมีการแยกบทบาทที่ดีได้
- การแยกบทบาทสำหรับ “Key KMS” ของ AWS สามารถทำได้โดยการจำกัดบทบาทผู้ดูแลระบบ AWS สำหรับ “Key KMS” ของ AWS ที่ถูก Assign
การเข้ารหัสระดับ Bucket โดย Default:
- หากคุณระบุวิธีการเข้ารหัสที่ระดับ Bucket วิธีการเข้ารหัสนั้นจะถูกถือเป็นวิธีการเข้ารหัสเริ่มต้น หากคุณไม่ได้ระบุวิธีในระดับ Object
- หากคุณระบุวิธีการเข้ารหัสที่ระดับ Object วิธีนี้จะถือเป็นวิธีการเข้ารหัสแทนที่การตั้งค่าระดับ Bucket
สรุป:
คำอธิบายข้างต้นจะช่วยให้ทุกคนที่ต้องการทราบว่า SSE-C, SSE-S3 และ SSE-KMS แตกต่างกันยังไง แม้ว่านี่จะเป็นการเปรียบเทียบง่ายๆ แต่หลายคนงงเป็นประจำ ในฐานะ Cloud Architect เป็นสิ่งสำคัญมากสำหรับเราที่จะต้องเข้าใจแนวคิดง่ายๆ เหล่านี้เมื่อเราเจาะลึกแนวคิดที่จริงจังยิ่งขึ้น
Thank You!

Last edited: